Client Failover
CLIENT FAILOVER
Today, I am going to talk about automatic failover.
Not just about cluster failvover (primary failure and standby taking over) but from client point of view.
Yes, PostgreSQL 10 is out since october 5th and 11 is on its way. It has (among others) a new awesome feature. Client can reconnect automaticaly to cluster after failure to either RO or RW instance.
So, here are some questions you might have :
- Is it easy to setup ?
- How much downtime ?
- Above all else : Is the damn thing working ?
In the Beginning…
Which HA ?
To cut it short, I chose REPMGR.
Configuration is 3 nodes (1 primary and 2 standbys) plus a witness server. In case you wonder, this last player serves as as casting vote in a situation of doubt over which node needs to be promoted.
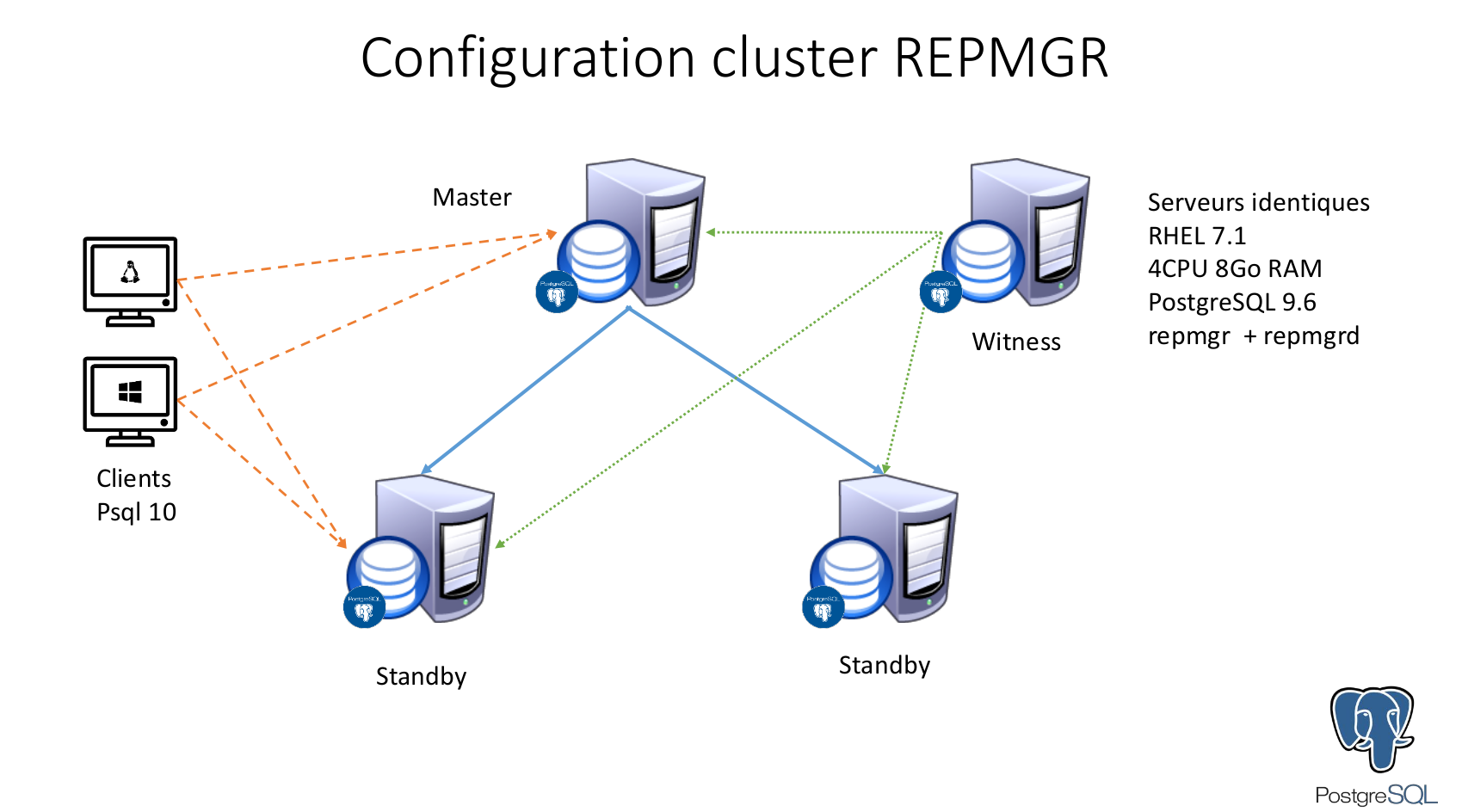
Here is an extract from repmgr.conf:
cluster=test_repmgr
node=4
node_name=node4
conninfo='port=5432 host=server1 user=repmgr dbname=repmgr'
failover=automatic
promote_command='repmgr standby promote -f /etc/repmgr.conf --log-to-file'
follow_command='repmgr standby follow -f /etc/repmgr.conf --log-to-file'
# the server's hostname or another identifier unambiguously
# associated with the server to avoid confusion
logfile='/var/log/repmgr/repmgr-9.6.log'
pg_bindir=/usr/pgsql-9.6/bin/
master_response_timeout=5
reconnect_attempts=3
reconnect_interval=5
retry_promote_interval_secs=10
Here is what’s expected:
Downtime = master_response_timeout + reconnect_attempts*reconnect_interval
Roughly 5 + 3*5 = 20 secondes of downtime for the database.
A man who is his own lawyer…
Once configuration is setup, how can one measure downtime? What needs to be done to reconnect the client to the new primary as soon as it is available?
The solution is automatic client failover.
This is entirely about the client. The clusters are all in version 9.6. It is important to notice that in order to benefit from this feature it is not necessary to install PG10 on the clusters, older versions will do just fine.
The client is only looking for the first node available. READ-ONLY (RO): It will pick any node (primary or secondary). READ-WRITE (RW): It will pick the first writable node (primary).
Implications are important, with a solution to automatically failover connections, it is no longer necessary to rewrite the connection string manually. The client is going to regain a connection and be instrumental in the measurement of downtime.
Figuring how to setup the connection string properly
Let us do a little bit of reading here and there. This will allow us to get a pretty good idea on how to proceed. Essentially:
-
We need to mention wether we need to connect on a primary (RW) or on a any cluster standby or primary (RO). Here of course, for writes failover we need to set up a connection string pointing to a primary server.
-
But that’s not all. We need to specify a list with all the nodes of our configuration with the ports (all the more if they are different from one another).
Practical matter
Here is a short extract from the script I wrote we these informations (and fumbling with it a little) you will get a better grasp of the way to proceed:
TIME_RES=10000 # time resolution in µs
MONITORING_DB=monitoring_replication
PORT_1=5432
PORT_2=$PORT_1
PORT_3=$PORT_1
HOST_1=server1
HOST_2=server2
HOST_3=server3
CONNINFO="postgresql://"$HOST_1":"$","$HOST_2":"$PORT_2","$HOST_3":"$PORT_3"/"$MONITORING_DB"?target_session_attrs=read-write"
Once connection has been restored, I will be able to establish a time frame of downtime and quantify how much writes have been lost during failover.
Quantum Leap: How to measure it?
I used usleep to write in a log table every 10ms (see note for more details) using the connection string described earlier.
Here is a link to the tool used for this test: monitoring_replication. It allowed me to measure downtime during failover. Installation and user guide are provided in the README file.
Another file in the Wal
In order to test our setup, we need to prompt a failure on the primary.
An easy way to achieve this, is to flood the WAL folder with files.
Once the failure is caused and the failover triggered, we will take a look at the repmgrd.log and then at the log table created and supplied with constant INSERTs for this purpose.
Here is an extract from the repmgrd.log file that exibits the failure as it has occured.
The detection occurs line 2.
The last three lines match the promotion of the standby.
Please note that the timestamp shows 21 seconds until promotion.
log node 2 (standby failover)
[2017-07-13 10:29:25] [ERROR] connection to database failed: could not connect to server: Connection refused
Is the server running on host "server1" (172.134.11.45) and accepting
TCP/IP connections on port 5432?
[2017-07-13 10:29:25] [ERROR] unable to connect to upstream node: could not connect to server: Connection refused
Is the server running on host "server1" (172.134.11.45) and accepting
TCP/IP connections on port 5432?
[2017-07-13 10:29:25] [ERROR] connection to database failed: could not connect to server: Connection refused
Is the server running on host "server1" (172.134.11.45) and accepting
TCP/IP connections on port 5432?
[2017-07-13 10:29:25] [WARNING] connection to master has been lost, trying to recover... 15 seconds before failover decision
[2017-07-13 10:29:30] [WARNING] connection to master has been lost, trying to recover... 10 seconds before failover decision
[2017-07-13 10:29:35] [WARNING] connection to master has been lost, trying to recover... 5 seconds before failover decision
[2017-07-13 10:29:40] [ERROR] unable to reconnect to master (timeout 5 seconds)...
[2017-07-13 10:29:45] [NOTICE] this node is the best candidate to be the new master, promoting...
[2017-07-13 10:29:46] [NOTICE] Redirecting logging output to '/var/log/repmgr/repmgr-9.6.log'
[2017-07-13 10:29:46] [ERROR] connection to database failed: could not connect to server: Connection refused
Is the server running on host "server1" (172.134.11.45) and accepting
TCP/IP connections on port 5432?
[2017-07-13 10:29:46] [ERROR] connection to database failed: could not connect to server: Connection refused
Is the server running on host "PCYYYPFE" (172.134.11.99) and accepting
TCP/IP connections on port 5432?
[2017-07-13 10:29:46] [NOTICE] promoting standby
[2017-07-13 10:29:46] [NOTICE] promoting server using '/usr/pgsql-9.6/bin/pg_ctl -D /appli/postgres/test_repmgr/9.6/data promote'
[2017-07-13 10:29:48] [NOTICE] STANDBY PROMOTE successful
Let’s have a look a the inserts performed by our little tool with a time resolution of an insert every 10ms. Here is part of our log table during the operation.
| pk | time |
|---|---|
| 5876 | 2017-07-13 10:29:24.221169+02 |
| 5877 | 2017-07-13 10:29:24.277367+02 |
| 5878 | 2017-07-13 10:29:24.330156+02 |
| 5879 | 2017-07-13 10:29:24.388040+02 |
| 5880 | 2017-07-13 10:29:24.441046+02 |
| 5881 | 2017-07-13 10:29:24.493518+02 |
| 5882 | 2017-07-13 10:29:24.545547+02 |
| 5883 | 2017-07-13 10:29:24.597415+02 |
| 5884 | 2017-07-13 10:29:24.649334+02 |
| 5885 | 2017-07-13 10:29:24.701244+02 |
| 5886 | 2017-07-13 10:29:24.753549+02 |
| 5911 | 2017-07-13 10:29:46.685232+02 |
| 5912 | 2017-07-13 10:29:46.832526+02 |
| 5913 | 2017-07-13 10:29:46.886040+02 |
| 5914 | 2017-07-13 10:29:46.939793+02 |
| 5915 | 2017-07-13 10:29:46.997917+02 |
| 5916 | 2017-07-13 10:29:47.053968+02 |
| 5917 | 2017-07-13 10:29:47.108371+02 |
Writes start again after 21 seconds. Well, it seems the client fulfilled its duty perfectly.
Live to see another SELECT…
New writes are performed after 21 seconds, but 25 INSERTS are missing (5886-5911). The client receives an error when INSERTS fail to succeed. When the writes are starting again, the client informs us about the success.
Conclusion
As we can see, the failover works just fine, and we do get new writes on the newly promoted primary after the failure. In the end, downtime lasted only 21 seconds and the failover itself - client and database - lasted under a second.
The writes also paused when no node was online. The error the clients gets is not given here, however when you get it, you know you can confirm with some proper investigations and take the necessary steps.
Moreover, we saw that once the failover has been performed, some lines were missing from the log table. Those INSERTS need to be played again.
note
It is possible to increase the sampling rate. Nevertheless, I chose this rate to take into consideration the order of magnitude of the system scales:
- (greatly) under total expected downtime (somewhere around 20s)
- under the time necessary to perform the failover databasewise (around 1s)
- above server time: connection to the cluster, syslogs, Postgres logs, CPU frequency… Otherwise, our measurement could influence the results by making too many INSERTS.
That would have modified performances: can you imagine an insert every nanosecond with nanosleep ? We would reach the billion (1,000,000,000) tps just for the sake of logging. With a measurement every 10ms, we stay in the 100 tps which in turn reaches 8 million inserts a day, and it is actually an honorable amount of transactions.